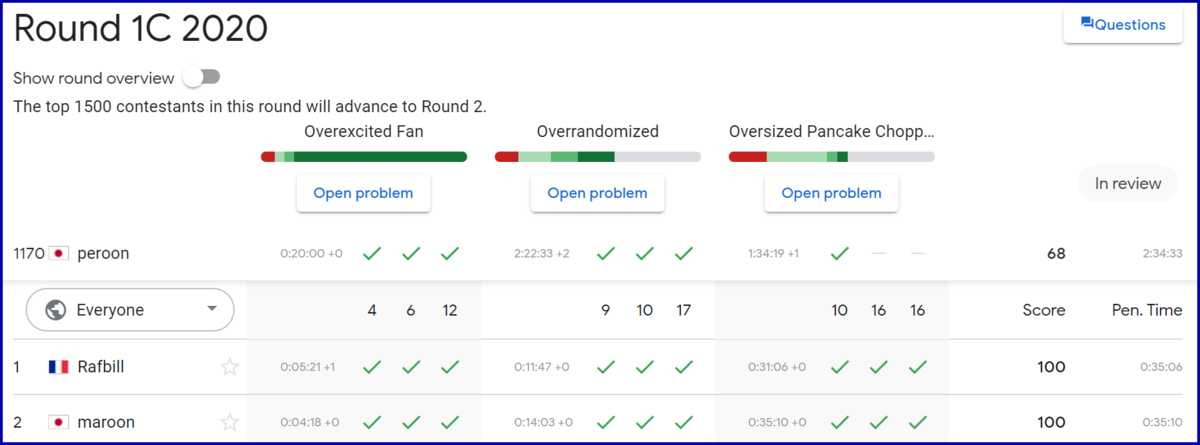
Round 1C 2020
https://codingcompetitions.withgoogle.com/codejam/round/000000000019fef4
予選突破🎉
- A✅✅✅
- B✅✅✅
- C✅❌❌
B問題 Overrandomized
1 (テストケース数) 2 (最大桁数) 20 P (以下、データが10000行) この10000行を「ログ」と呼ぶことにする 37 PU 26 L 95 FB 24 L ...
// 答えの例 Case #1: TPFOXLUSHB
Test Set 1 (Visible Verdict)
- U=2桁まで
- ログを見れば出現する10個のアルファベットは分かる
- 2桁のログ、例えば「37 PU」を見ればPは0じゃないと分かる
- 10000件もあれば「0に対応するアルファベット」は分かる
- 2桁までなのでM=1であるログは必ずあると考えてよく、その時のアルファベットが1で確定する
- M=2であるログも存在し、上の行の情報も使えば2に対応するアルファベットも一意に定まる
- 以下同様
Test Set 2 (Visible Verdict)
- U=16桁まで
- 0に対応するアルファベットは分かっているとする
- 残りのアルファベット9種が、1から9のどれかに対応する
- 各ログを見て「数字の長さ=文字列の長さ」であるものだけに注目する
- 例:34123 HGJFK
- これを見ると、Hは1,2,3のどれかに絞られる
- 10000行使えば1種類に絞られるものが出てきて、そのアルファベットの値は確定する
- その情報も使うことで、2種類まで絞られていたアルファベットも1種類に絞られて確定する
- 以下同様
- 私の実装では、可能性が残っている箇所をフラグで管理した
Test Set 3 (Visible Verdict)
- 0に対応するアルファベットは分かっているとする
- ログの数字の部分がすべて-1として提供される。なのでTest Set 2の先端を見る手法は使えない
- 例:-1 HGJFK
- 統計で暗号解読をする気持ちになろう
- 例の場合、Hは9である可能性は低く、1である可能性は高い
- よって、ログの先頭アルファベットの統計をとり、1番多く出現したアルファベットを1と推定する
- 以下同様
感想
- 2完が必要なのはRound 1Aと同様だった。難易度のバランスがうまく調整されている
- とはいえ簡単なTest Setから1歩1歩進むことで知見が得られる。今回の場合は先頭を見るということ。(leading digit)
- 統計・確率なので普段の競プロとは毛色が違った
- 参加者が増えているので通過難易度は上がっているものの、時間ギリギリで通って嬉しい
- 英文はとりあえずdeeplにつっこむ
 (新潮文庫)")
- 作者:サイモン シン
- 発売日: 2007/06/28
- メディア: 文庫